We have started building a weather workspace inside the broader astrocartography and mundane research environment in Vox Stella. The goal is not to present a finished weather prediction engine. The goal is to build a structured research surface where weather-oriented astrological logic can be organized, inspected, and benchmarked without hiding the reasoning layers.
If you need the wider product context first, the Astro Clock overview and the Windows product page explain how Vox Stella separates its workspaces. This article is narrower. It is about the current weather workspace, what the runtime exposes, and what the benchmark branches currently justify saying in public.
Editor's note: This feature is still under development. As of April 19, 2026, the figures below refer to doctrine/coverage benchmarking and predictive hindcast benchmarking. They do not validate prospective weather prediction, and this feature should be described as benchmarked research tooling rather than a finished predictive system.
A weather workspace, not a black-box claim
The current runtime is a first-pass research system. It resolves a forecast chart, the latest relevant seasonal ingress, and the latest lunar trigger, then evaluates them through three visible layers:
- Seasonal framework
- Trigger signals
- Locality cues
That matters because the point of the workspace is not to hide interpretation behind a single score. The user can inspect the weather family, review the resolved context, see which rules were matched, and scan timing windows across a place or region with the reasoning layers still visible.
The active seed-runtime families are intentionally narrow
At this stage, the seed runtime is focused on four active families:
- Flood risk
- Hurricane pressure
- Severe convective pressure
- Wind event pressure
That narrowness is deliberate. It is more useful to expose a smaller research surface with transparent logic than to claim broad weather coverage before the underlying runtime earns it.
Locality is present, but it is still a proxy layer
One of the hardest parts of weather research in astrology is locality. This is where frameworks often become vague exactly when they need to become more precise.
The current workspace does include locality logic, but it is still a proxy layer, not a finished full map-grade weather runtime. Right now, the app uses forecast-chart angular emphasis plus horizon and meridian target-zone intersections as locality proxies. That gives the workspace a meaningful first layer of place sensitivity, but it is not yet the same thing as a fully developed operational mapping system.
That distinction should stay public and explicit. The current weather workspace is research-driven, benchmarked, and still being expanded.
Two benchmark branches are doing two different jobs
The benchmark framing matters because this feature should be judged by how well it can be audited, not by how confidently it can be marketed. We currently maintain two separate weather benchmark branches, and they are not interchangeable.
1. Doctrine/coverage benchmark
The first branch is a doctrine/coverage benchmark. It freezes source-backed weather doctrine and historical cases into a dataset that can be reviewed and validated against the runtime. As of April 19, 2026, that branch contains 47 benchmark rows across 30 unique cases: 13 source-alignment doctrine cases and 34 historical benchmark rows.
This branch is about whether the runtime remains connected to the source logic it claims to preserve. It is a discipline and coverage check, not a claim of live predictive validation.
2. Predictive hindcast benchmark
The second branch is a predictive hindcast benchmark. It asks a narrower question: if we scan a known historical place across a benchmark window, does the model concentrate pressure near the real event window, and does that target window outperform matched non-event control windows at the same place?
That is a useful research question, but it is still a hindcast question. It is not the same thing as proving prospective weather prediction, and it should be described that way.
Current hindcast figures as of April 19, 2026
As of April 19, 2026, the predictive hindcast suite contains 11 cases. Out of those 11 cases, 8 passed alignment criteria, 7 were exact target-window passes, and 1 was a near pass.
The family-level picture is mixed, which is exactly why the benchmark language needs to stay careful.
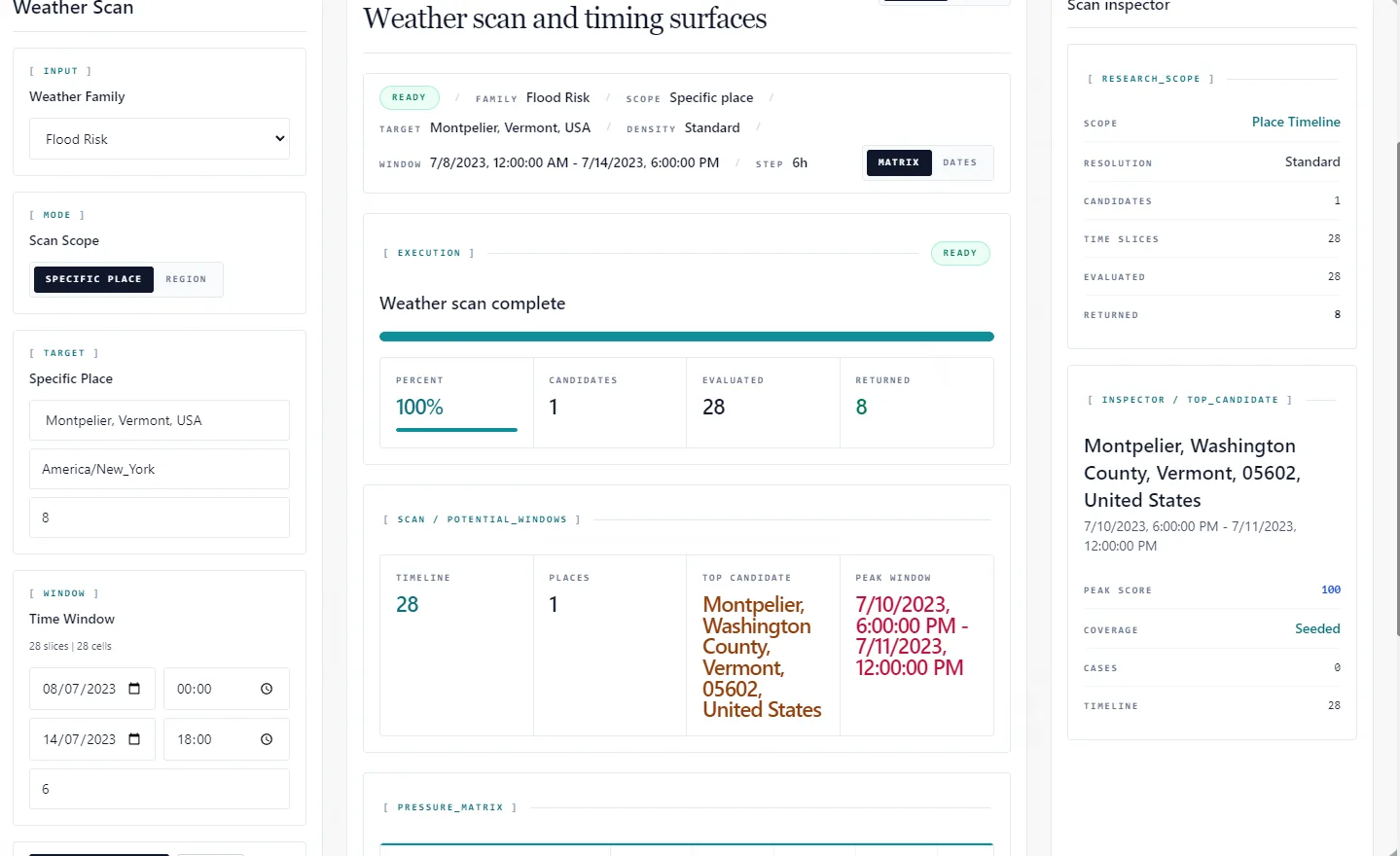
Why the Montpelier flood holdout case matters
The current flood-risk results are the strongest part of the hindcast suite, and that includes the two novel holdout flood cases. The Montpelier, Vermont case is worth showing because it illustrates the standard we are actually trying to hold: the workspace should expose the scan context, the returned window, and the locality surface in a way that can be inspected rather than hand-waved.
That is still a benchmarked research use case, not a claim that the system is ready for prospective weather forecasting. But it is the kind of transparent holdout example that makes the current state of the work easier to judge honestly.
The false-positive policy is deliberately strict
The current hindcast suite penalizes false positives when same-place non-event control windows outperform the real event window. That rule matters because it stops the benchmark from rewarding a runtime that is noisy everywhere and only looks good after the fact.
The current place-timeline benchmark also allows nearby-place spillover and does not treat it as failure. That is intentional. Nearby-place spillover is a different question from same-place target concentration, and it should be tested separately rather than folded into the same score.
What these results do and do not justify saying
The current conclusion is simple and should stay simple. The weather workspace is promising, usable for research, and benchmarked more seriously than most experimental astrology tooling. But it is still a developing system.
It is not a finished predictive weather product. It is not a validated prospective weather engine. It is a benchmarked research workspace with visible reasoning layers, doctrine checks, hindcast tests, and explicit limitations.
That is the standard we want for this feature: transparent, inspectable, and progressively harder to fool. If the benchmark gets stronger, we will say that. If a family stays weak, we will say that too.
FAQ
Is this a weather prediction engine?
No. The weather workspace is still under development and should be described as benchmarked research tooling, not as a finished predictive system.
What are the three visible runtime layers?
The current runtime exposes three visible layers: seasonal framework, trigger signals, and locality cues.
What does predictive hindcast mean here?
It means scanning known historical places across benchmark windows to see whether the model concentrates pressure near the real event window and whether that target window beats matched same-place control windows. It does not prove prospective prediction.
Is locality fully solved in the current workspace?
No. Locality is still a proxy layer built from forecast-chart angular emphasis and horizon or meridian target-zone intersections. It is not yet a finished full map-grade weather runtime.
Which family is strongest right now?
As of April 19, 2026, flood risk is the strongest family in the current hindcast suite at 4/4 exact, including 2/2 novel holdout flood cases.